Intuition Pin: Prompt Engineering
Research Track

prompt engineering
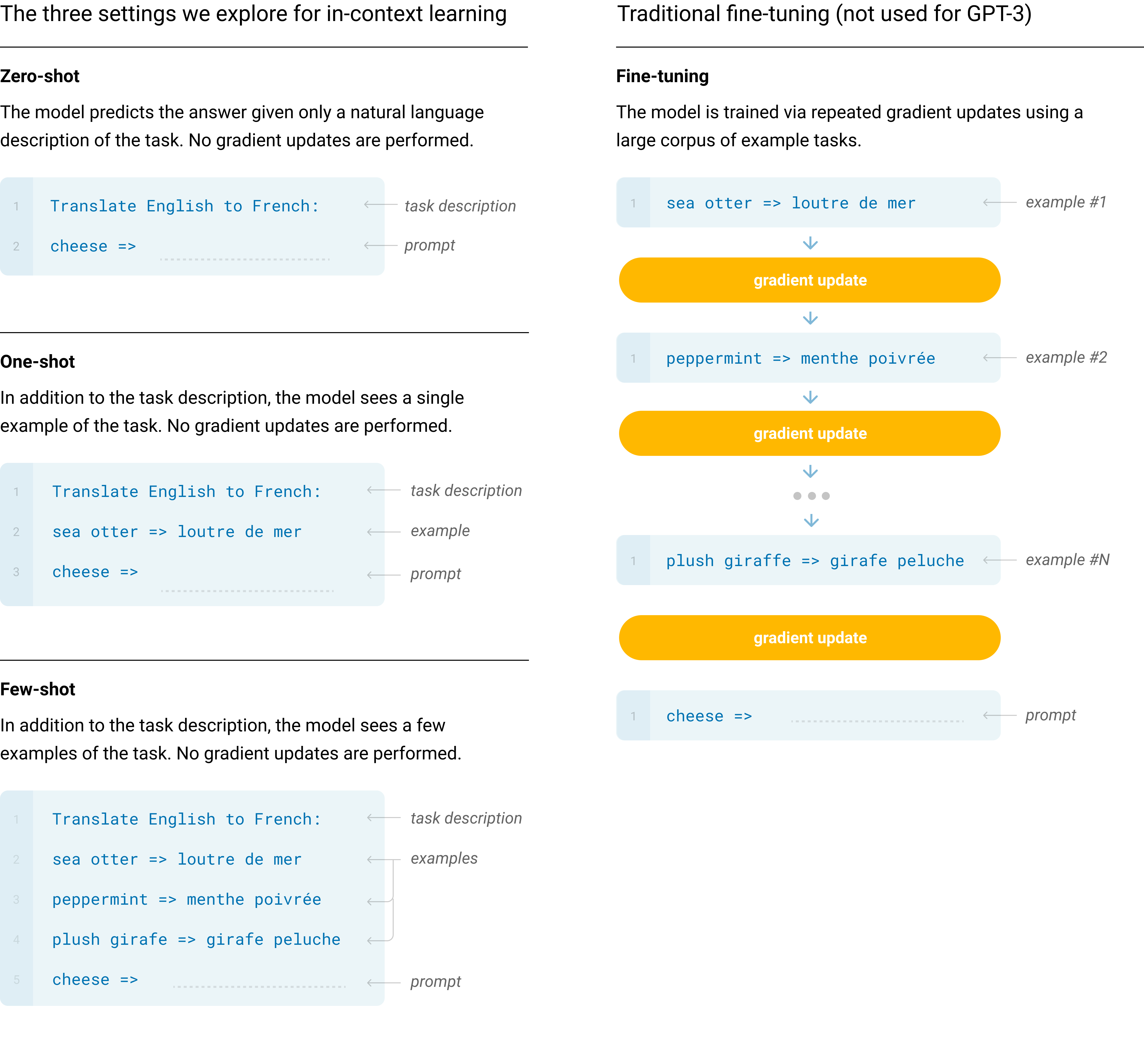
Few shot prompting
Language Models are Few-Shot Learners Brown et al. 2020
-
Define few-shot prompting as the setting where the model is given a few demonstrations of the task at inference time for conditioning.
-
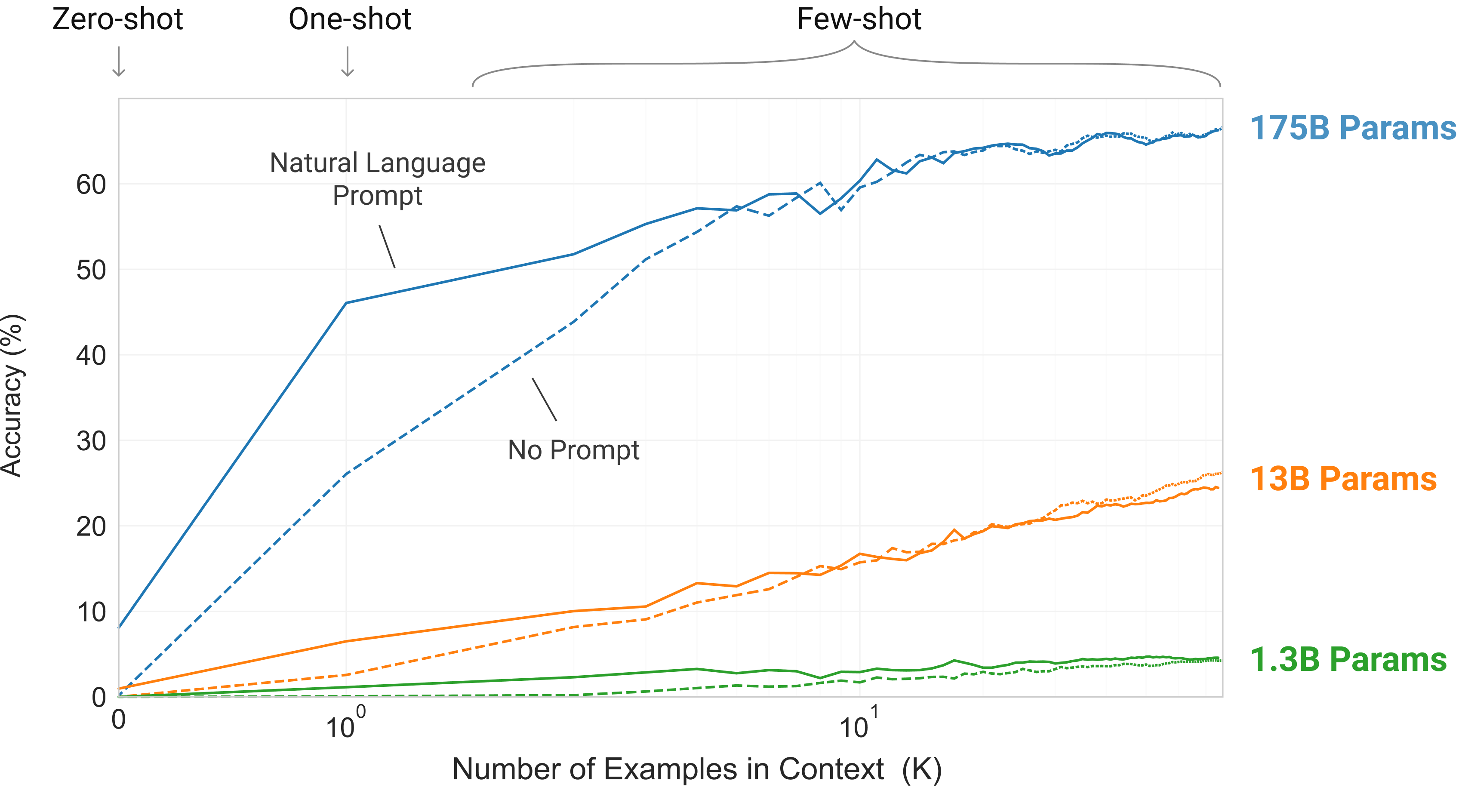
Larger models make increasingly efficient use of context information.
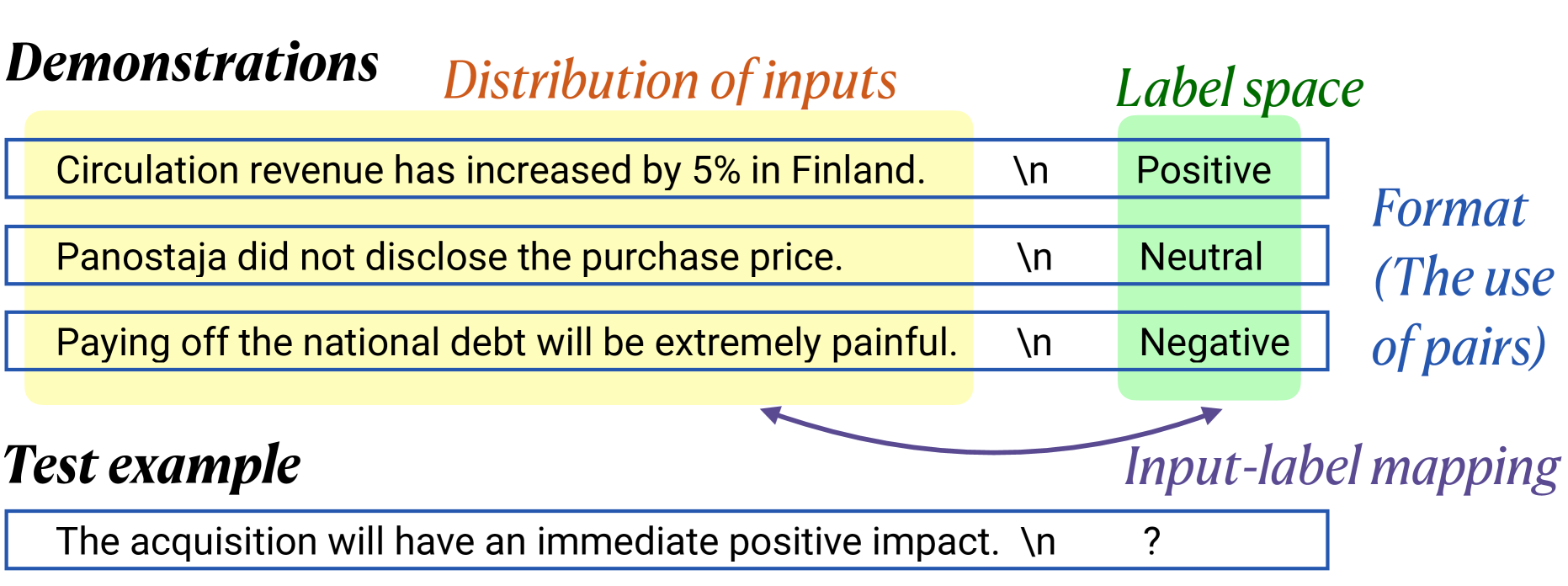
Few shot prompting: Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? Min et al. (2022)
- Format is really important. It includes (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence.
- The label can be random; it won’t impact the result.
Chain of Thoughts (COT)
Manual COT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models Wei et al. (2022)
- Give some practical demonstrations on how reasoning can significantly increase logical reasoning capability.
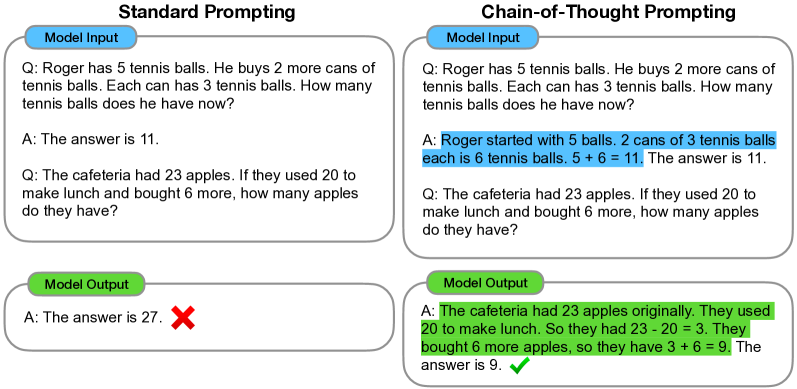
Zero Shot COT: Large Language Models are Zero-Shot Reasoners Kojima et al. (2022)
- In most cases, you do not need to give examples. You just need to add the sentence, "Let's think step by step."

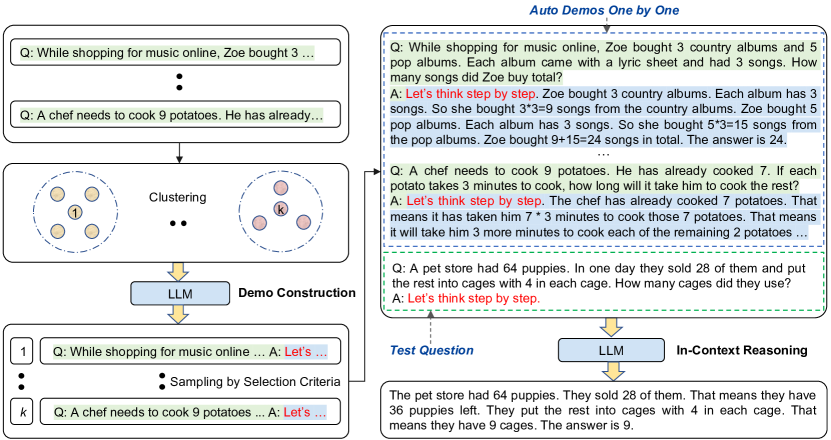
Auto-COT: Automatic Chain of Thought Prompting in Large Language Models Zhang et al. (2022)
- In some cases, LLMs need manual demonstration. You can provide examples to LLMs and leverage their ability to generate reasoning chains with the prompt "Let's think step by step" to avoid manual work.
- LLMs can make mistakes in previous steps. Diversity matters and reduces the error effect. Auto COT adds functionality to maximize diversity by clustering the examples and sampling from each cluster.
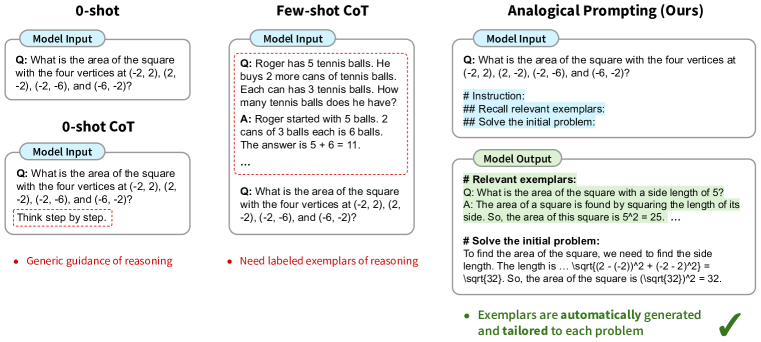
Analogical reasoning: Large Language Models as Analogical Reasoners Yasunaga et al. (2023)
- Prompts language models to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the given problem.
- Obviates the need for labeling or retrieving exemplars, offering generality and convenience; it can also tailor the generated exemplars and knowledge to each problem, offering adaptability.
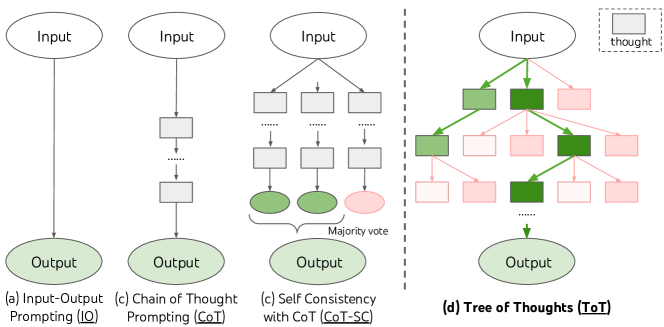
Tree of Thoughts (TOT): Tree of Thoughts: Deliberate Problem Solving with Large Language Models Yao et el. (2023)
Contrastive Chain-of-Thought Prompting
- provides both valid and invalid reasoning demonstrations, to guide the model to reason step-by-step while reducing reasoning mistakes.
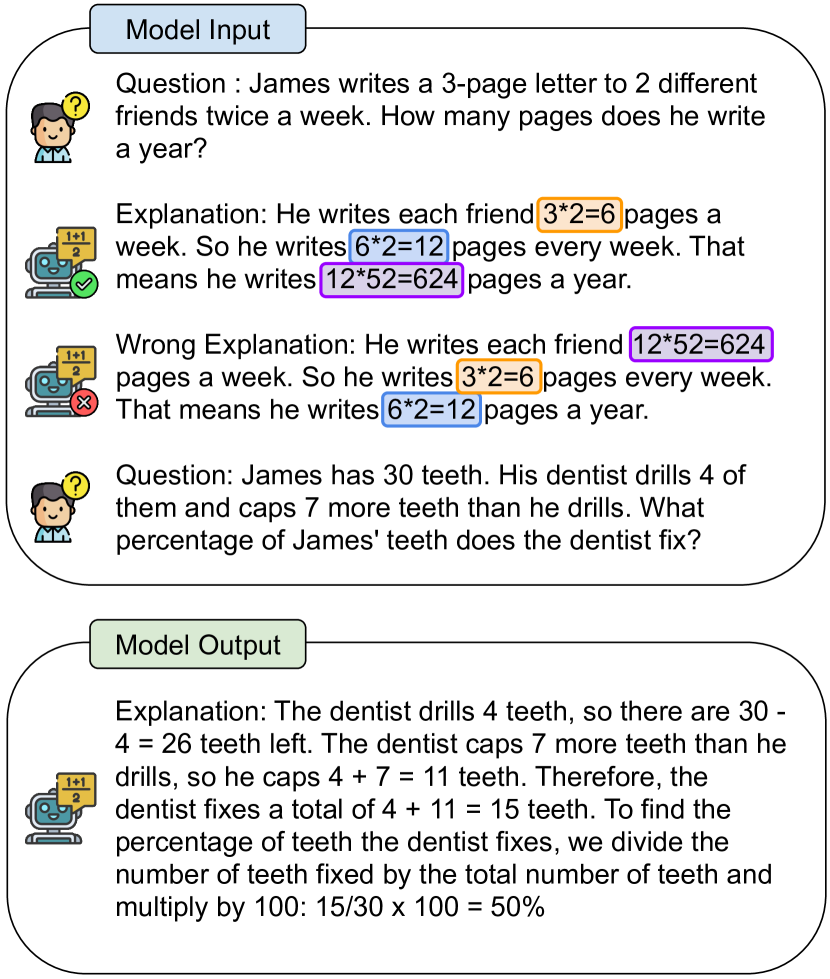
Choose Consistency Result
Self Consistency: Self-Consistency Improves Chain of Thought Reasoning in Language Models Wang et al. (2022)
- Sample from the language model’s decoder to generate a diverse set of reasoning paths; each reasoning path might lead to a different final answer, so we determine the optimal answer by marginalizing out the sampled reasoning paths to find the most consistent answer in the final answer set.
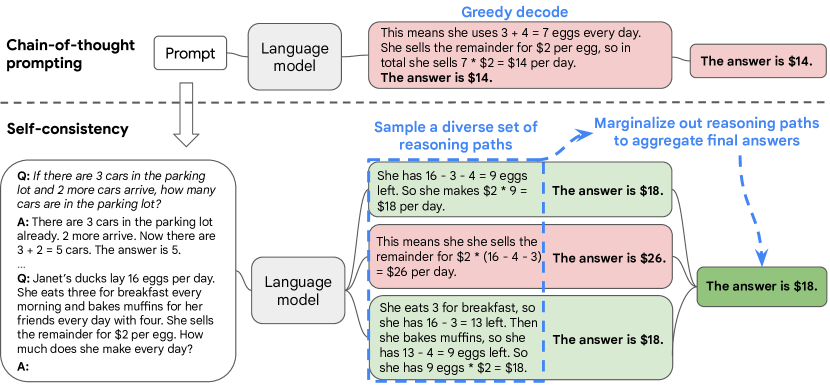
Breaking down to sub problems
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models Zhou et al (2022)
- The key idea in this strategy is to break down a complex problem into a series of simpler subproblems and then solve them in sequence. Solving each subproblem is facilitated by the answers to previously solved subproblems.
 .
.
Self Reflection
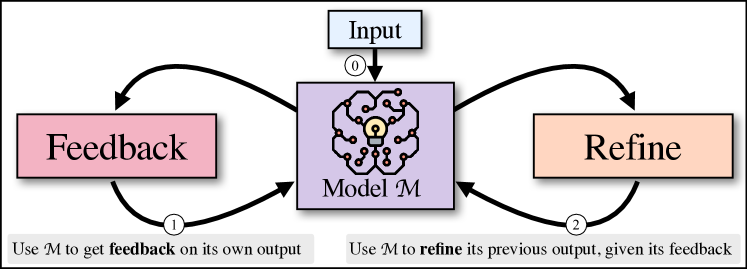
Self-Refine: Iterative Refinement with Self-Feedback
- The main idea is to generate an initial output using an LLMs; then, the same LLMs provides feedback for its output and uses it to refine itself, iteratively
- Outputs generated with Self-Refine are preferred by humans and automatic metrics over those generated with the same LLM using conventional one-step generation, improving by ~20% absolute on average in task performance.
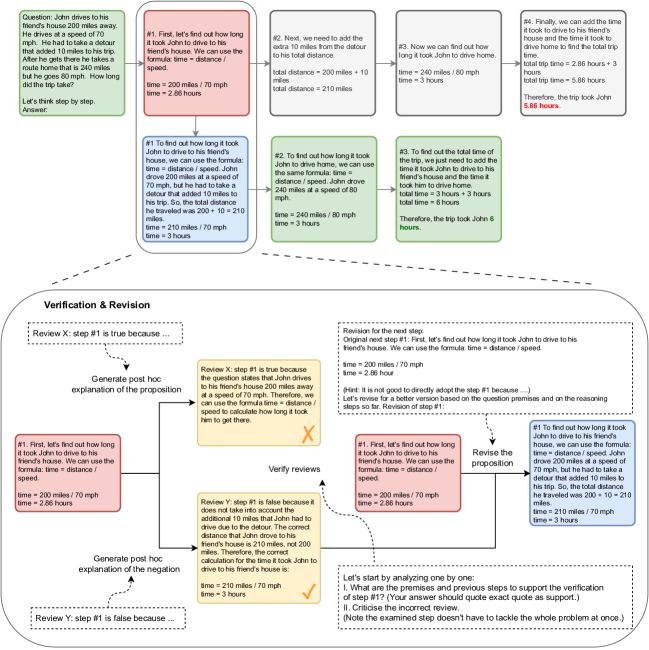
Logical COT(LOT): Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic Zhao et al 2023
- In CoT, the failure of entailment (red ) makes the rest of the deduction untrustworthy (grey), consequently impeding the overall success of the deduction. In contrast, LogiCoT is designed to think-verify-revise: it adopts those who pass the verification ( green) and revise ( blue) those who do not, thereby effectively improving the overall reasoning capability.
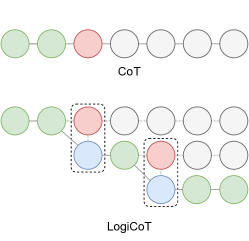
- Verification and revision is down through reductio ad absurdu. detailed progress see below.
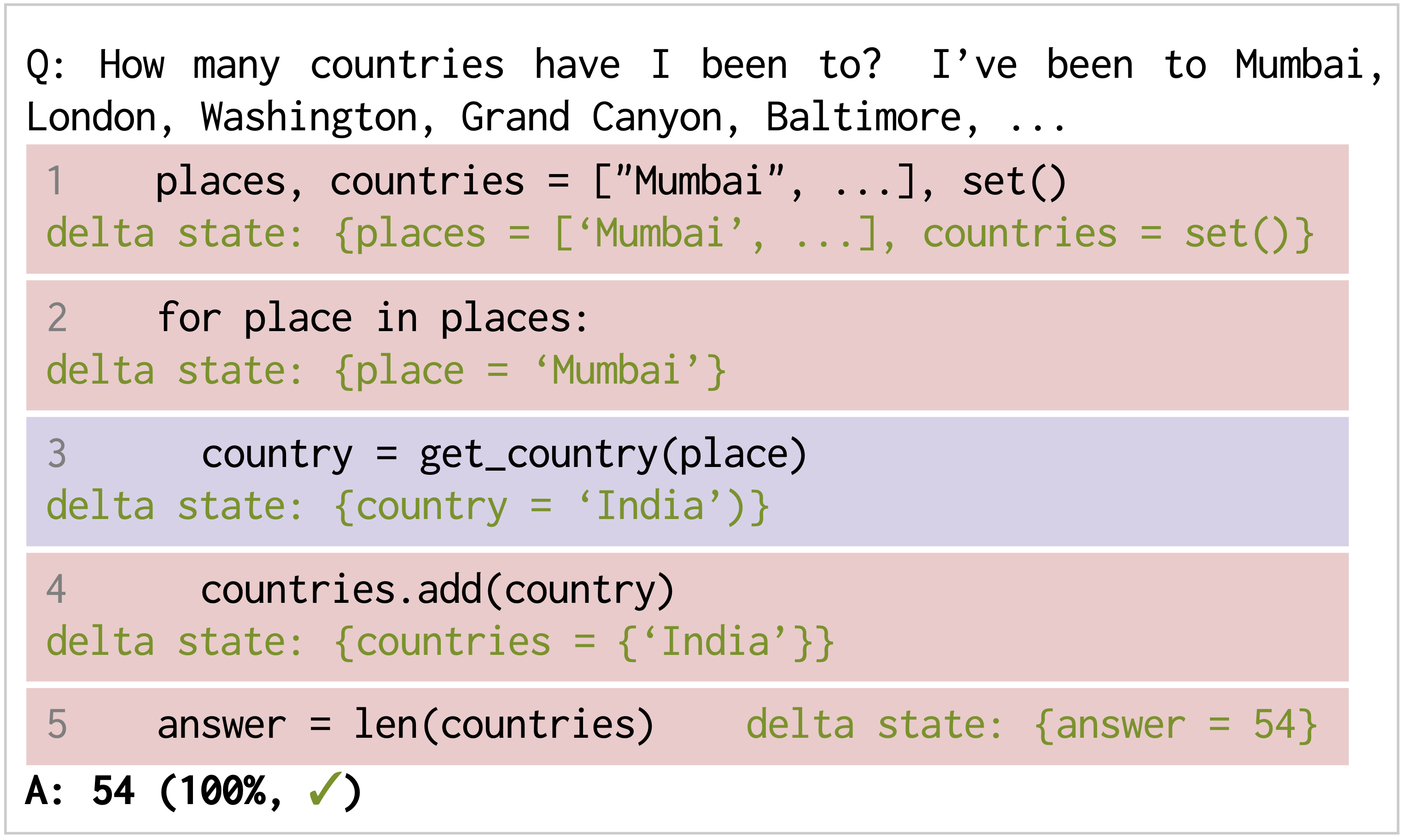
Use Program to aid reasoning
Program of Thoughts Prompting (POT): Disentangling Computation from Reasoning for Numerical Reasoning Tasks Chen et al 2022
- Use language models (mainly Codex) to express the reasoning process as a program and executes the generated programs to derive the answer
- PoT can show an average performance gain over CoT by around 12% across all the evaluated dataset

PAL: Program-aided Language Models Gao et al 2022
- Decomposing the natural language problem into runnable steps, while solving is delegated to the interpreter
- exceed COT in 13 mathematical, symbolic, and algorithmic reasoning tasks from BIG-Bench Hard and other benchmarks.

Chain of Code: Reasoning with a Language Model-Augmented Code Emulator Li et al 2023
- Encourage LMs to format semantic sub-tasks in a program as flexible pseudocode that the interpreter can explicitly catch undefined behaviors and hand off to simulate with an LM (as an “LMulator").
- CoC broadens the scope of reasoning questions that LMs can answer by “thinking in code".
Get External Information
ReAct: Synergizing Reasoning and Acting in Language Models Yao et al., 2022
- generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with and gather additional information from external sources such as knowledge bases or environments.
- Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes prevalent issues of hallucination and error propagation in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generating human-like task-solving trajectories that are more interpretable than baselines without reasoning traces.

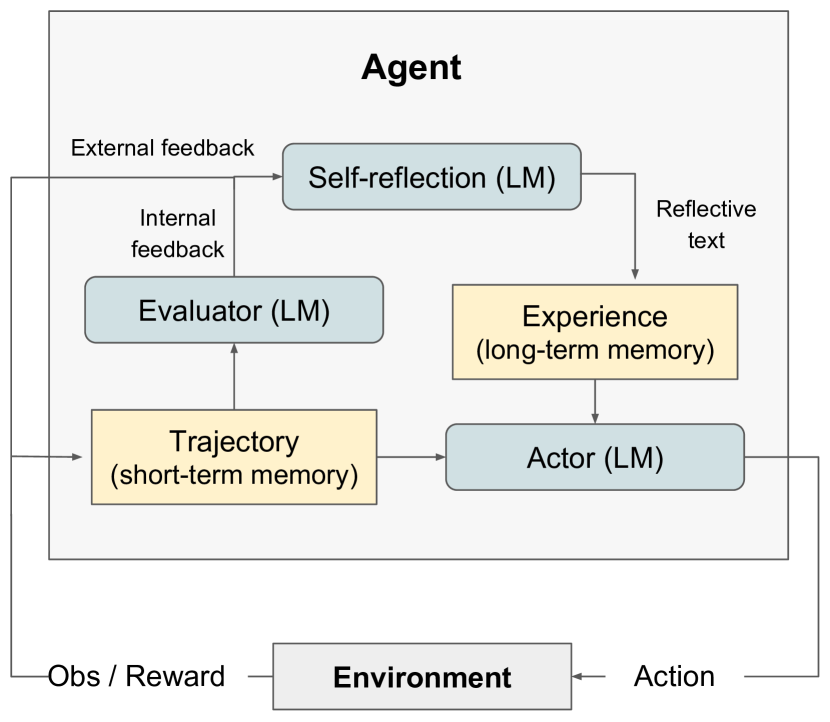
Reflexion: Language Agents with Verbal Reinforcement Learning Shinn et al. 2023
Reflexion consists of:
- An Actor: The Actor is built on a large language model (LLM) that is specifically prompted to generate the necessary text and actions based on state observations.
- An Evaluator: The Evaluator component of the Reflexion framework assesses the quality of the outputs produced by the Actor.
- Self-Reflection: The Self-Reflection model, instantiated as an LLM, generates verbal self-reflections to provide valuable feedback for future trials, playing a crucial role in the Reflexion framework.
- Memory: The trajectory history serves as short-term memory, while outputs from the Self-Reflection model are stored in long-term memory.

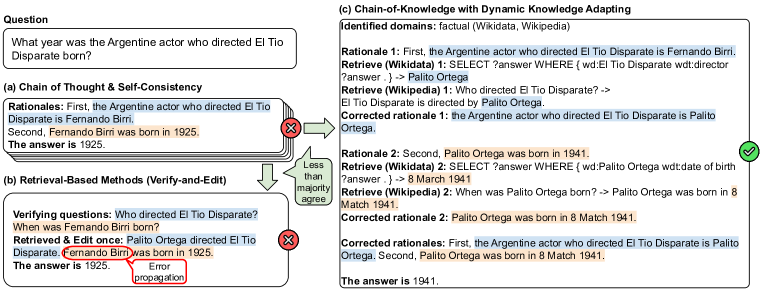
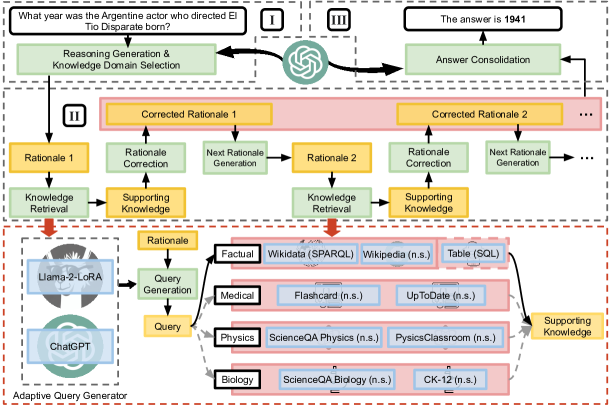
Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources Li et al 2023
CoVE
Chain-of-Verification Reduces Hallucination in Large Language Models Dhuliawala et al 2023
- CoVE is a method to reduce hallucination by (i) drafts an initial response, then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response.

Prompt automation and optimization
APE: Large Language Models Are Human-Level Prompt Engineers Zhou et al., (2022)
- Treat the instruction as the “program,” optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function
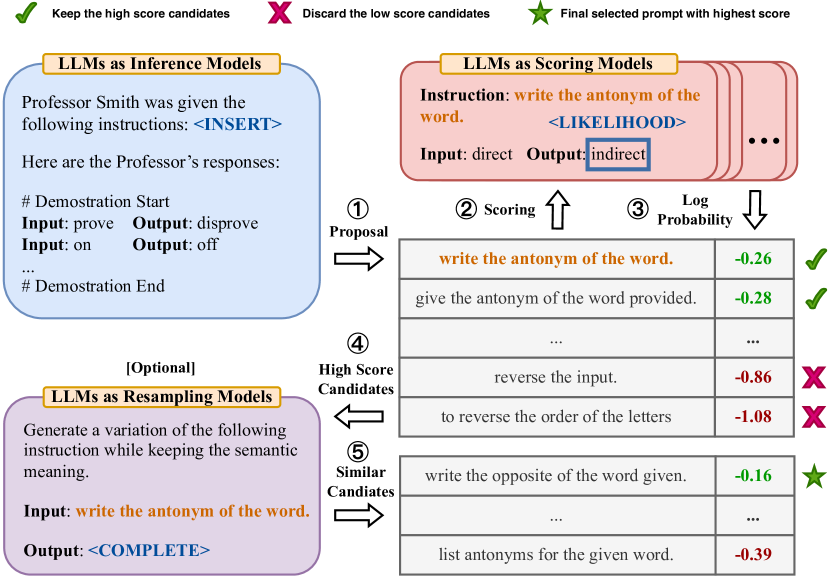
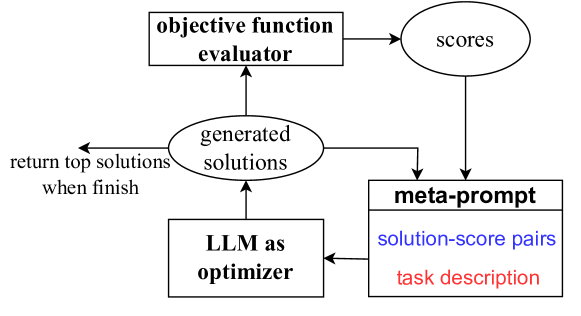
OPRO: Large Language Models as Optimizers Yang et al 2023
- In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step.